Some AWS quirks you learn on the way
I recently listed some problems I’ve run into when learning how to “cloud”. Going through those, I noticed that they were mainly in my approach to building an architecture, and there’s more about AWS specifics that I want to write about. I’m now listing some details that I found odd. Some of them I can say that I now understand, but some others still feel silly.
Extending your EC2 storage
Extending your EBS (Elastic Block Storage) volumes will still require you to resize your filesystem in your EC2 instance. When you need to extend your EBS, it’s usually because you’re running out of disk space in you instance. While this seems like a common task, it is not possible to do everything directly from the AWS Console. This makes more sense once you understand more deeply what EBS really is. The aim of EBS is to provide a storage volume that is attachable to an instance, once plugged-in to this volume, it acts as a physical hard drive. With an an EBS you can still make several choices unknown to the hardware provider, such as creating software RAID arrays, you can use MBR or GPT, you can format and create as many partitions you want with a filesystem of your liking. It is now obvious that when you want to “increase disk space” you need to understand your context, even if you created your EC2 instance with all the defaults.
The docs on this were not always as good as they are now, and this sporadic task that should take a had my eyes rolling from time to time. Not because it took too long to figure out, but because I couldn't ever get it right the first time.
Still, I have to admit that I should not have needed to do this as many times in the first place: I had this need because I was not doing logs correctly. And I’m not talking about accumulating logs forever. Running out of space due to logging can also be a problem when your log rate increases as your application grows. If you feel like you are resizing mainly due to logging, reconsider your approach with tools like logrotate (to rotate older logs) or aggregators (such as Loki or Logstash).
Don't delete the storages
By default, terminating an EC2 instance will also delete the associated EBS volume. This means that data that you have on disk will be lost. You can prevent losing this data by detaching the volume from the instance before terminating. Stopping an instance will have no effect on the EBS.
This can come in useful when you no longer need the EC2 instance, but you need to keep a backup of the disk. Just keep in mind that this is an expensive backup when compared to S3 storage, so consider moving this data over to S3, or at least to a cold storage volume.
Rebooting vs Stop/Start
There are quite a few subtle differences between "Rebooting" and "Stop/Start" an EC2 instance which are important be aware of. When you reboot, your instance retains all the resources, that is to also say your IP address remain the same and your billing is not interrupted. On the other hand, you can think of “stopping an instance” as freeing up your current “hardware” back to AWS virtual pool. Once you start the instance again, you will be assigned new resources, the EBS is re-attached to your new “hardware” and everything is booted up. This means new IP address, so if you refer to this machine via IP (for instance in DNS records) you will need to update the references. Your billing hour will also restart.
Some operations on your EC2 instance required it to be stopped, this includes upgrading or downgrading instance type, so there’s no choice there. If you feel like your allocated instance is acting up on you, “Stop/Start” is a good strategy to force refresh it.
Caches will only be available in your VPC
Elasticache instances will only be accessible to other running services on the same VPC. This necessarily means that the instance must be in the same region as the other services. There are some workarounds, but I prefer to have a cleaner and easier to explain stack.
In my case, I was using Elasticache as a task queue, since Elasticache is the only managed Redis/Memcached service available. At times, it would have been useful for me to have the information of this node available across regions, i.e. an EC2 instance running in Ireland would use the Elasticache instance running in Frankfurt. This would be possible - and even cheaper - through a managed EC2 instance running Redis, but that would require a bit more maintenance.
With all this in mind, it makes perfect sense to keep the caches available only inside the VPC that uses it (security wise it’s a no-brianer). Still, if this was the default of a configurable behavior, the number of use-cases covered by Elasticache would be a lot bigger, particularly since Redis is widely used in these other use-cases.
Some mess-ups aren’t yours
Some services will mess up and not tell you about it. Recently, I had some confusing CPU spikes on an instance that were fixed without any intervention from me at all. I figure this could have been due to faulty hardware or something, but I should have been warned about it.
I did not get a single information about this, not even after this was solved. As I mentioned earlier, Stop/Start a instance would also most likely have fixed this problem.
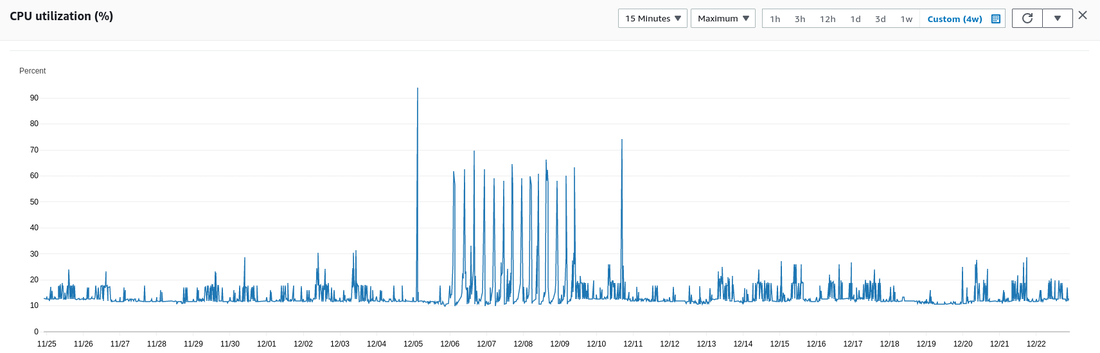 Notice the spikes between 12/06 and 12/11.
Notice the spikes between 12/06 and 12/11.
Conclusion
Every time I open up AWS console web-app, I feel like I live in an AWS bubble. The services that I use are a very small fraction of the universe. AWS had to make some decisions at some point when building each and every one of these services, so the quirks are unavoidable. Furthermore, most choices I have run into are sensible, but not hard to document. At times, I had to trust some StackOverflow answers without sources.
Finally, I feel like when a service is malfunctioning or borderline failing, AWS has no feedback and a very uneventful service page. This makes it hard for critical clients to trust the service. Transparency is also a choice, and there is room for improvement on that.